Benchmark
We provide a collection of concrete tasks inspired by various pain points we have observed in real-world ML development workflows. Many of these pain points require systematic solutions which we evaluate in this benchmark.
Background
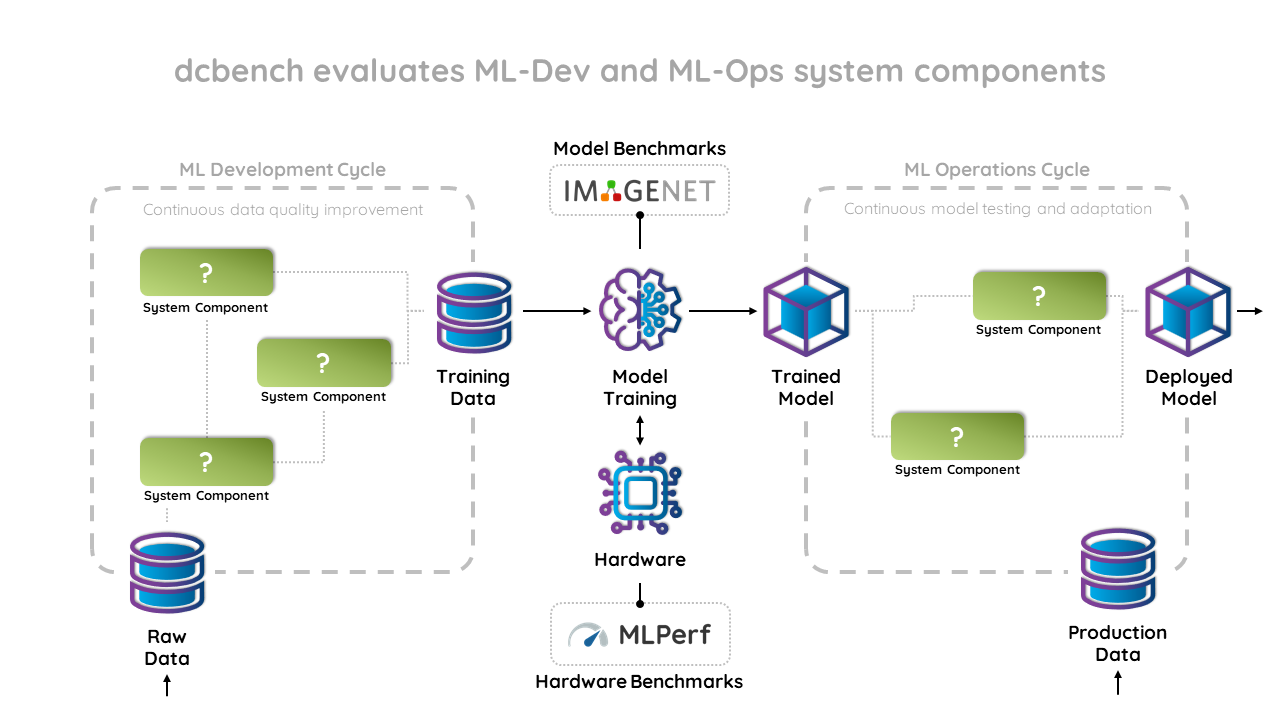
Machine learning practitioners of today are expected to perform many kinds of tasks. Apart from model training, a typical workflow consists of various data and model management tasks, as well as model and data debugging. Without good tooling, it will become nearly impossible to juggle the ever increasing complexity of ML projects. Our benchmark seeks to inspire the community to focus their effort towards building better ML systems.
How it works?
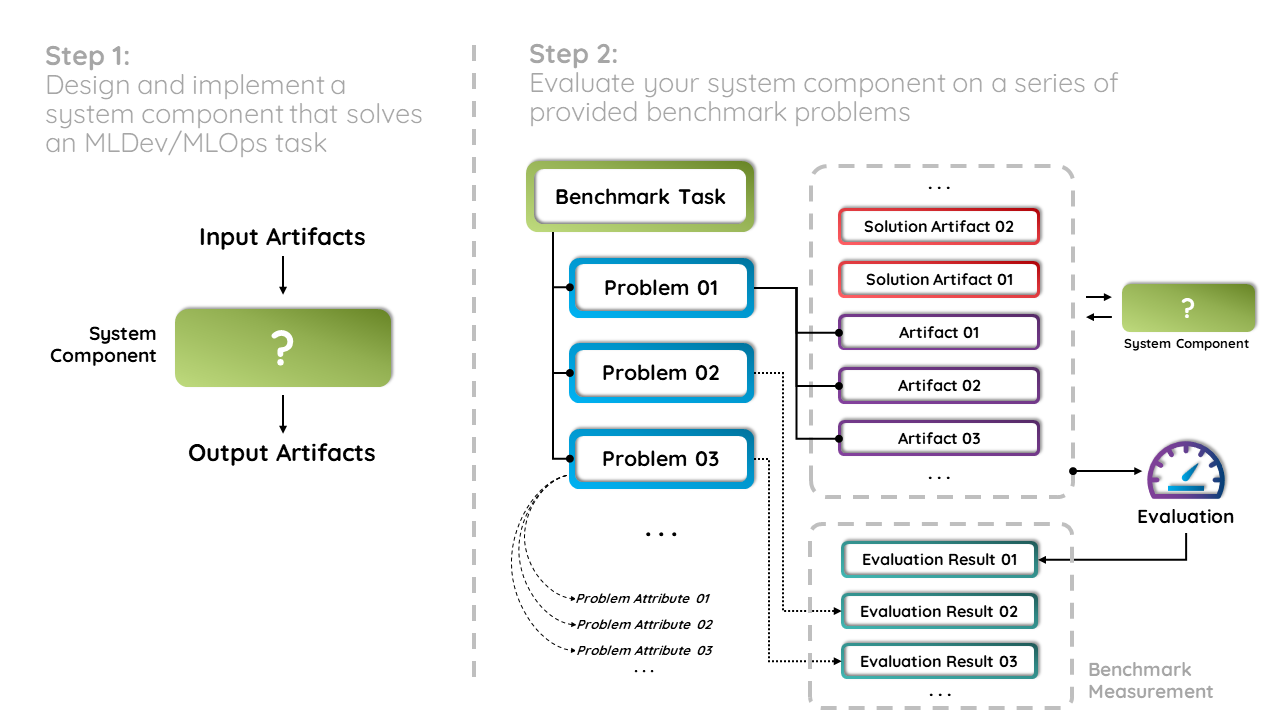
The benchmark is made up of a growing list of tasks. Each task corresponds to some specific pain point that, based on our observations, occurs commonly in ML workflows. Furthermore, the design of each task assumes the existence of a tool that systematically solves it.
For each task we provide a curated collection of problems. Each one is a concrete instantiation identified by various attributes such as source dataset or budget, as well as a set of artifacts such as datasets or models. For each problem, the participant is expected to provide a solution made up of a specified set of artifacts.
When a solution is produced for all problems of a given task, the participant is invited to submit them using our submission form. After being thoroughly evaluated, we will make the submission appear on our leaderboards.
Getting Started
We provide a Python package to make it super easy to interact with the benchmark, test your solution and upload your submissions:
pip install dcbench
We recommend using an interactive development environment such as Jupyter Notetbooks. You can explore the list of tasks provided:
import dcbench
dcbench.tasks
After selecting the task you want to tackle, we recommend you study the task-specific instructions, including the list of artifacts that come with each problem and the expected artifacts to include in a solution. You can explore individual problems as such:
# List problem instances.
dcbench.budgetclean.problems
# Get a specific problem instance.
problem = dcbench.budgetclean.problems["p001"]
Given a problem, you can access its artifacts as such:
# List problem artifacts.
problem.artifacts
# Get a specific artifact.
artifact_1 = problem.artifacts["artifact_1"]
Once you solve the problem and produce the corresponding solution artifacts, you can construct a solution:
solution = problem.solve(artifact_1=my_artifact_1)
We can evaluate our solution and produce a score for any given problem:
result = problem.evaluate(solution)
Tasks
When it comes to data preparation, data cleaning is often an essential yet quite costly task. If we are given a fixed cleaning budget, the challenge is to find the training data examples that would would bring the biggest positive impact on model performance if we were to clean them.
Even a relatively good ML model could still parform particularly poorly on certain clusters of data. Identifying those clusters is crucial for debugging. In this task we look for methods that can automatically discover such "problematic data clusters".
It is common practice to strive towards obtaining as much training data as possible. However, large datasets increase management and model training costs. Not all data examples are equally important. Given a large training dataset, what is the smallest subset you can sample that still achieves some threshold of performance?
Publications
S Eyuboglu,
[DEEM] Proceedings of the Sixth Workshop on Data Management for End-To-End Machine Learning
Abstract
The development workflow for today’s AI applications has grown far beyond the standard model training task. This workflow typically consists of various data and model management tasks. It includes a “data cycle” aimed at producing high-quality training data, and a “model cycle” aimed at managing trained models on their way to production. This broadened workflow has opened a space for already emerging tools and systems for AI development. However, as a research community, we are still missing standardized ways to evaluate these tools and systems. In a humble effort to get this wheel turning, we developed dcbench, a benchmark for evaluating systems for data-centric AI development. In this report, we present the main ideas behind dcbench, some benchmark tasks that we included in the initial release, and a short summary of its implementation.

